

A Flash model just outperformed its Pro predecessor and not by a narrow margin. We’re talking about the Gemini 3.5 Flash and Gemini 3.1 Pro here. On the coding and agentic benchmarks that matter most to developers, Gemini 3.5 Flash wins 11 of 15 published comparisons against Gemini 3.1 Pro, while running approximately 4x faster and costing 25% less per token. The catch is that independent evaluators have also measured a 61% hallucination rate, a figure Google did not volunteer on launch day. My testing suggests the same; hallucinations are very much real with the 3.5 Flash. But here’s what the numbers actually tell you.
Gemini 3.5 Flash vs Gemini 3.1 Pro – What We’re Comparing
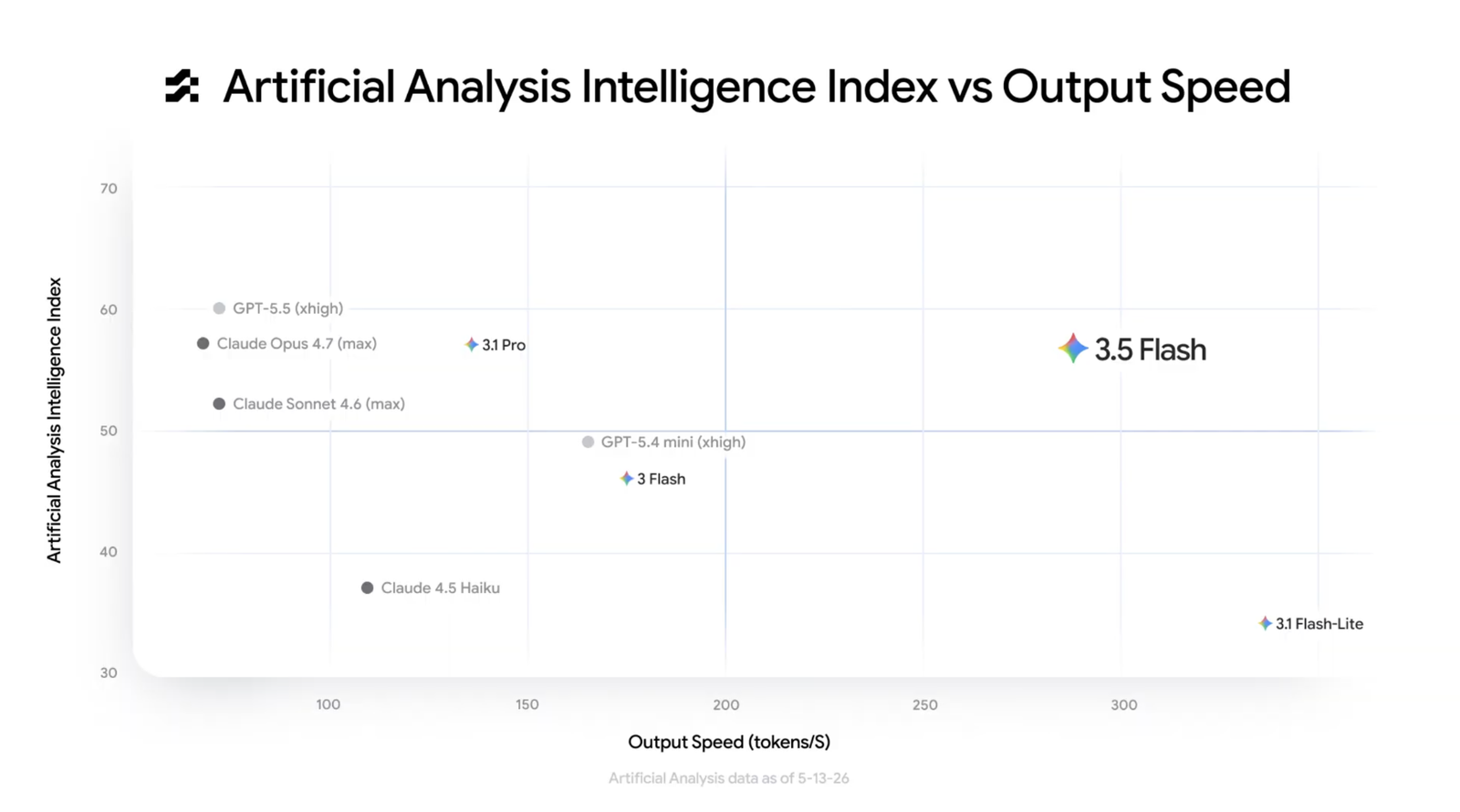
Gemini 3.5 Flash shipped at Google I/O 2026 on May 19 as a General Availability release with the model ID gemini-3.5-flash. Gemini 3.1 Pro, which launched in February 2026, is still in preview status (gemini-3.1-pro-preview), meaning its SLA is less stable than a GA release. Both models share a 1M-token context window with 65,536 max output tokens. But their architectures reflect very different design priorities.
Google DeepMind CTO Koray Kavukcuoglu stated plainly at I/O that 3.5 Flash “outperforms our latest frontier model, 3.1 Pro, on nearly all the benchmarks.” That framing — a Flash model beating a Pro model — broke an expectation that had held for years across the industry. Flash models were cheaper and faster; Pro models were smarter. Gemini 3.5 Flash collapses that hierarchy, at least in the domains where developers spend most of their time.
The model is built on the Gemini 3 Flash reasoning foundation with explicit thinking levels (low, medium, high) that trade quality for cost and latency. The published benchmark results use the high configuration. That distinction matters: if you’re using the API and don’t set thinking_level explicitly, the default dropped from high to medium when migrating from the preview version — a silent behavior change that has bitten developers who assumed continuity.
Gemini 3.5 Flash vs Gemini 3.1 Pro for Coding – Benchmark Breakdown
These are the published numbers, sourced from Google’s model card and verified by independent evaluators, including Artificial Analysis and WaveSpeed AI.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro | Winner |
| Terminal-Bench 2.1 | 76.2% | 70.3% | 3.5 Flash (+5.9 pts) |
| MCP Atlas (tool use) | 83.6% | 78.2% | 3.5 Flash (+5.4 pts) |
| Finance Agent v2 | 57.9% | 43.0% | 3.5 Flash (+14.9 pts) |
| GDPval-AA Elo | 1656 | 1314 | 3.5 Flash (+342 Elo) |
| SWE-Bench Pro Public | 55.1% | 54.2% | Tie (within noise) |
| CharXiv Reasoning (multimodal) | 84.2% | 82.8% | 3.5 Flash |
| ARC-AGI-2 | 72.1% | 77.1% | 3.1 Pro (+5 pts) |
| 128K MRCR v2 (long-context) | Lower | Higher | 3.1 Pro |
| Humanity’s Last Exam | Lower | Higher | 3.1 Pro |
| BenchLM Aggregate | 87 | 92 | 3.1 Pro (+5 pts) |
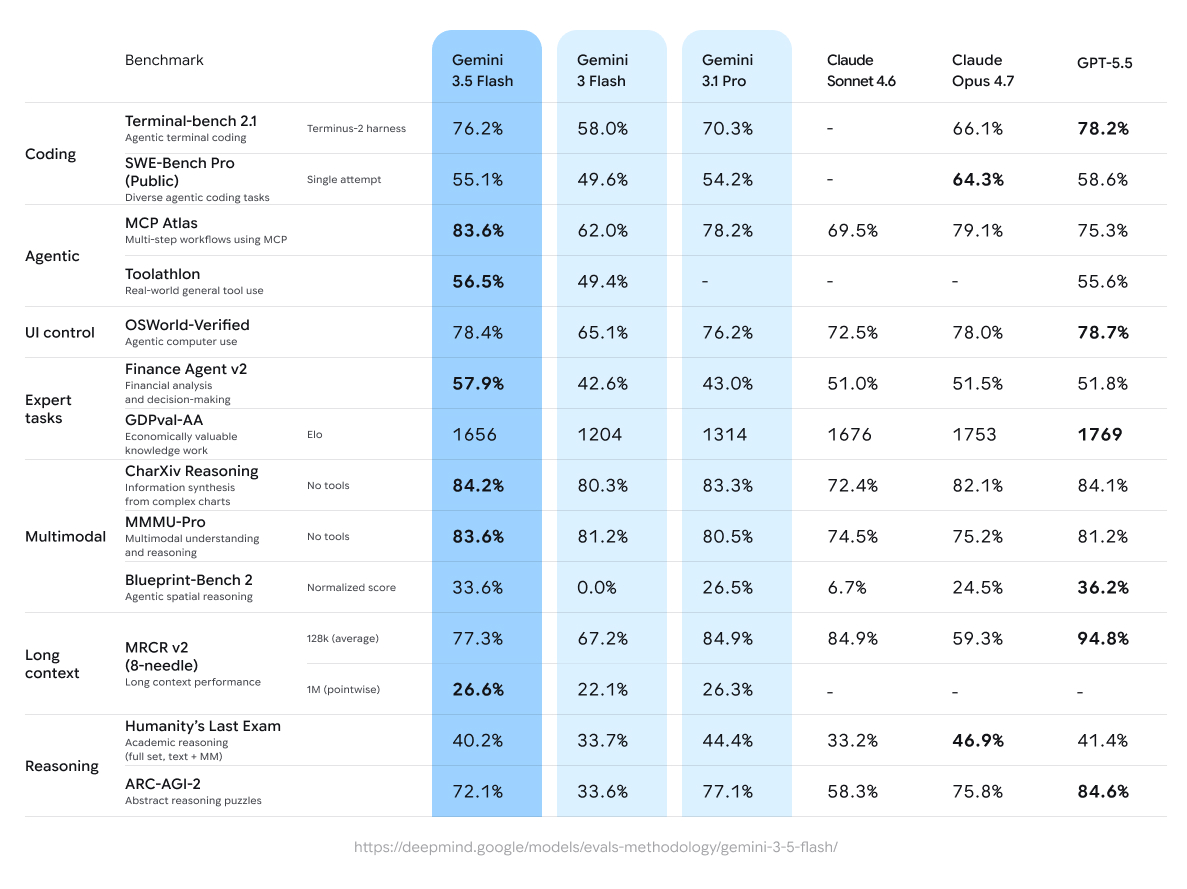
The BenchLM aggregate score is the number that complicates the narrative. Gemini 3.1 Pro leads 92 to 87 across the full suite, and its reasoning average of 77.1 outpaces Flash’s 74.7. On ARC-AGI-2 specifically — a proxy for abstract reasoning rather than task execution — 3.1 Pro’s 5-point lead is the largest single gap in the table. That gap also explains the aggregate: when you average across all dimensions, abstract reasoning and long-context retrieval pull 3.1 Pro ahead overall. Flash wins where it counts for most coding workflows; Pro wins where it counts for research-heavy or high-stakes reasoning tasks.
The Coding Tests That Matter Most for Developers
Terminal-Bench 2.1 is the most relevant benchmark for anyone using these models inside a CLI or CI environment. It measures the ability to execute multi-step terminal tasks — reading file system state, writing and running scripts, handling error output, and retrying. Gemini 3.5 Flash scores 76.2% versus 3.1 Pro’s 70.3%. That nearly 6-point gap is meaningful for automated pipelines where the model is operating the terminal rather than advising a human operator.
MCP Atlas tests scaled tool-use reliability — how well a model maintains correct tool invocations across extended multi-call sequences (8-15 calls per task, 4k-12k token context per call). Flash’s 83.6% beats 3.1 Pro’s 78.2% and also leads every competitor in the field, including Claude Opus 4.7 (79.1%) and GPT-5.5 (75.3%). For developers building autonomous agents that integrate web search, vector databases, and code execution sandboxes, this is the benchmark to weigh most heavily.
SWE-Bench Pro Public is closer to a practical measure of real-world bug fixing — the ability to resolve actual GitHub issues from open-source repositories. Scores of 55.1% (Flash) and 54.2% (Pro) are statistically tied. At parity on bug-fix quality, Flash wins on price and speed alone.
Finance Agent v2 is the biggest absolute gap in the table: 57.9% versus 43.0%, a nearly 15-point difference. This benchmark models complex, multi-step financial reasoning inside an agentic loop. The gap suggests Flash was specifically post-trained on agentic task completion in a way that 3.1 Pro was not.
Real-World Developer Results
One hands-on test that circulated post-launch widely came from a solo macOS developer (Tauri + Rust + Swift stack) who gave both models a 200-line Rust ADB device manager file containing 14 intentional bugs across four categories:
Bug breakdown used in the test:
- Logic bugs (main): 7, including post-execution timeout checking and undetected APK install failures
- Async bugs: 2, including a CPU-spinning busy loop and a potential data race
- ADB-specific traps: 3, including \r leftover in line endings and an uncleaned temp file
- Missing tests: 2 edge cases not covered
The 200-line threshold was chosen deliberately. Under 50 lines, models get lucky. Over 100 lines, older Flash-tier models had historically produced near-unusable code. The ADB-specific bugs were the real filter — catching them requires domain knowledge, not just Rust syntax awareness.
Both Gemini 3.5 Flash and 3.1 Pro were tested with an identical no-hint prompt: identify all bugs and provide corrected code with explanations. Gemini 3.5 Flash caught more of the ADB-specific traps and returned a cleaner corrected file, though the developer was careful to note this was a single task type in a controlled test. The hallucination complaints circulating on X may apply more to conversational and knowledge-retrieval tasks than to structured code review — though that distinction is itself an important qualifier.
The Hallucination Number Google Didn’t Publish
Artificial Analysis’s AA-Omniscience sub-evaluation measured a 61% hallucination rate for Gemini 3.5 Flash. This is a 31-point improvement over Gemini 3 Flash’s rate — a real and significant drop — but still high in absolute terms. Gemini 3.1 Pro’s hallucination rate is lower, which is the direct driver of its lead on knowledge-heavy benchmarks like Humanity’s Last Exam.
The practical implication is workload-specific:
- Code generation and agentic tasks: Hallucination is less dangerous because the output is executable and errors surface at runtime. Flash’s speed advantage compounds here — 289 tokens/second lets you iterate faster through failures.
- Retrieval-augmented generation (RAG) and fact-sensitive tasks: A 61% hallucination rate is a serious risk. Gemini 3.1 Pro is the safer choice for any workflow where the model’s factual claims need to be trusted without runtime validation.
- Instruction following structured outputs: This is where the community forum complaints have been loudest. A thread on the Google AI Developers Forum from May 22 reported that Flash “seems to perform worse than Gemini 3 Flash preview, especially in structured outputs and code execution tool with larger document attachments.” This tracks with the hallucination data and with the known behavior change around the thinking_level default.
Speed and Cost: The Real Decision Lever
At 289 tokens/second, Gemini 3.5 Flash is roughly 4x faster than frontier-tier alternatives and 70% faster than Gemini 3 Flash. This compounds in agentic workflows: Google demoed Flash running 93 parallel subagents and over 15,000 requests in 12 hours for under $1,000.
The pricing difference versus 3.1 Pro is consistent across the board:
| Pricing Item | Gemini 3.5 Flash | Gemini 3.1 Pro | Difference |
| Standard input (<200K tokens) | $1.50/M | $2.00/M | 25% cheaper |
| Standard output (<200K tokens) | $9.00/M | $12.00/M | 25% cheaper |
| Long input (>200K tokens) | $1.50/M (no tier) | $4.00/M | 62.5% cheaper |
| Long output (>200K tokens) | $9.00/M (no tier) | $18.00/M | 50% cheaper |
| Cached input | $0.15/M | $0.20/M | 25% cheaper |
The long-context pricing is the most striking line. Gemini 3.1 Pro doubles its output price past 200K tokens; Flash does not. For any workflow that regularly processes large codebases or documentation, that 50-62% discount on long-context tokens adds up quickly. Flash is also the default model now inside Antigravity CLI (agy) and the Gemini app, meaning most developers will encounter it before they ever configure a model preference.
Where 3.1 Pro Still Wins
It would be inaccurate to call this a clean Flash victory. Gemini 3.1 Pro holds real advantages in specific scenarios:
- Abstract reasoning under uncertainty: ARC-AGI-2’s 77.1% versus 72.1% is meaningful for tasks like algorithm design, proof construction, or complex debugging, where you can’t run the output to validate it.
- Long-context retrieval: Flash degrades faster than 3.1 Pro past 128K tokens on the MRCR v2 benchmark. Teams processing full codebases or large document archives in a single prompt should test this boundary against their specific context lengths.
- Instruction-following stability on complex system prompts: A thread from the Google AI Developers Forum in April 2026 noted that 3.1 Pro showed instruction-following drops on complex system prompts versus Claude Opus — but Flash’s behavior in this area appears less consistent still.
- GA vs. preview SLA: 3.1 Pro is still in preview. For enterprise teams with uptime requirements and SLA-backed contracts, Flash’s GA status is actually an argument in its favor — but for teams already integrated deeply with 3.1 Pro’s behavior, the preview stability has been acceptable.
What to Use for Which Coding Workload
- Agentic pipelines (multi-tool, long-horizon tasks): Flash, no contest. The GDPval-AA Elo gap of 342 points is the largest delta in the full benchmark table, and it reflects exactly what Flash was post-trained to do.
- Bug detection and code review on production files: Flash, based on both benchmarks and real-world testing results, with the caveat that domain-specific knowledge gaps may surface in less common language ecosystems.
- SWE-Bench-style issue resolution: Treat them as tied. Decide on cost and speed — both favor Flash.
- RAG or knowledge-intensive coding tasks: Lean toward 3.1 Pro until Flash’s hallucination rate improves or your pipeline has runtime validation to catch factual errors.
- Reasoning-heavy architecture design or algorithm analysis: 3.1 Pro is the safer bet, particularly if you cannot run the model’s suggestions through a compiler or test suite before acting on them.
A Gotcha Worth Flagging Before You Migrate
If you’re migrating from gemini-3-flash-preview to gemini-3.5-flash, set thinking_level explicitly in your API calls. The default shifted from high to medium between versions. Running medium instead of high gives you a faster, cheaper, and meaningfully less capable model than the one Google’s benchmark table describes. Several developers reported this in the week following launch, surprised that their outputs felt regressed despite switching to a nominally newer model.
Wrapping UP
Gemini 3.5 Flash vs Gemini 3.1 Pro for coding is not a close call for most developers — Flash wins the benchmarks that reflect real engineering work, costs less, and runs significantly faster. Terminal-Bench 2.1 (76.2% vs 70.3%), MCP Atlas (83.6% vs 78.2%), and the 14.9-point Finance Agent v2 gap tell a consistent story: Flash was built for execution, not just reasoning. The 61% hallucination rate is a real constraint that limits its use in fact-sensitive pipelines, and 3.1 Pro’s 5-point ARC-AGI-2 lead matters if abstract reasoning is your primary bottleneck. But for the majority of coding and agentic workflows, shipping on Flash today and watching for Gemini 3.5 Pro next month is the practical path forward.



