February 2026 has been, hands down, the most competitive month in the history of LLMs. Three (world-class) frontier models dropped within sixteen days: Claude Opus 4.6 on February 4, GPT-5.3-Codex on February 5, and Gemini 3.1 Pro on February 19. If you write code for a living, you’re drowning in choices for LLMs to assist you with your coding needs. Valid if confused. But let’s cut through the noise in this direct Gemini 3.1 Pro vs Opus 4.6 coding comparison.
Gemini 3.1 Pro is Google DeepMind’s latest reasoning model, built directly on the intelligence core of Gemini 3 Deep Think. Google released it first as a preview across AI Studio, Vertex AI, and the Gemini app. Its biggest architectural trait is native multimodality: the model processes text, images, video, and audio in the same interaction, and it carries a 1-million-token context window. That context ceiling matters for developers working across large codebases.
Claude Opus 4.6 is Anthropic’s flagship model for February 2026. It builds on the agentic foundation Anthropic established with Opus 4 in May 2025, and it sharpens that model’s focus on sustained, multi-step reasoning for software engineering tasks. Opus 4.6 has also gained a 1 million token context window in beta, closing the gap that previously separated it from Gemini. Both models support extended thinking modes, though they implement the idea differently.
Gemini 3.1 Pro vs Opus 4.6 – Coding Benchmarks Comparison
This is where things get genuinely interesting. Neither model dominates cleanly, and the benchmark splits reveal specific design priorities baked into each system.
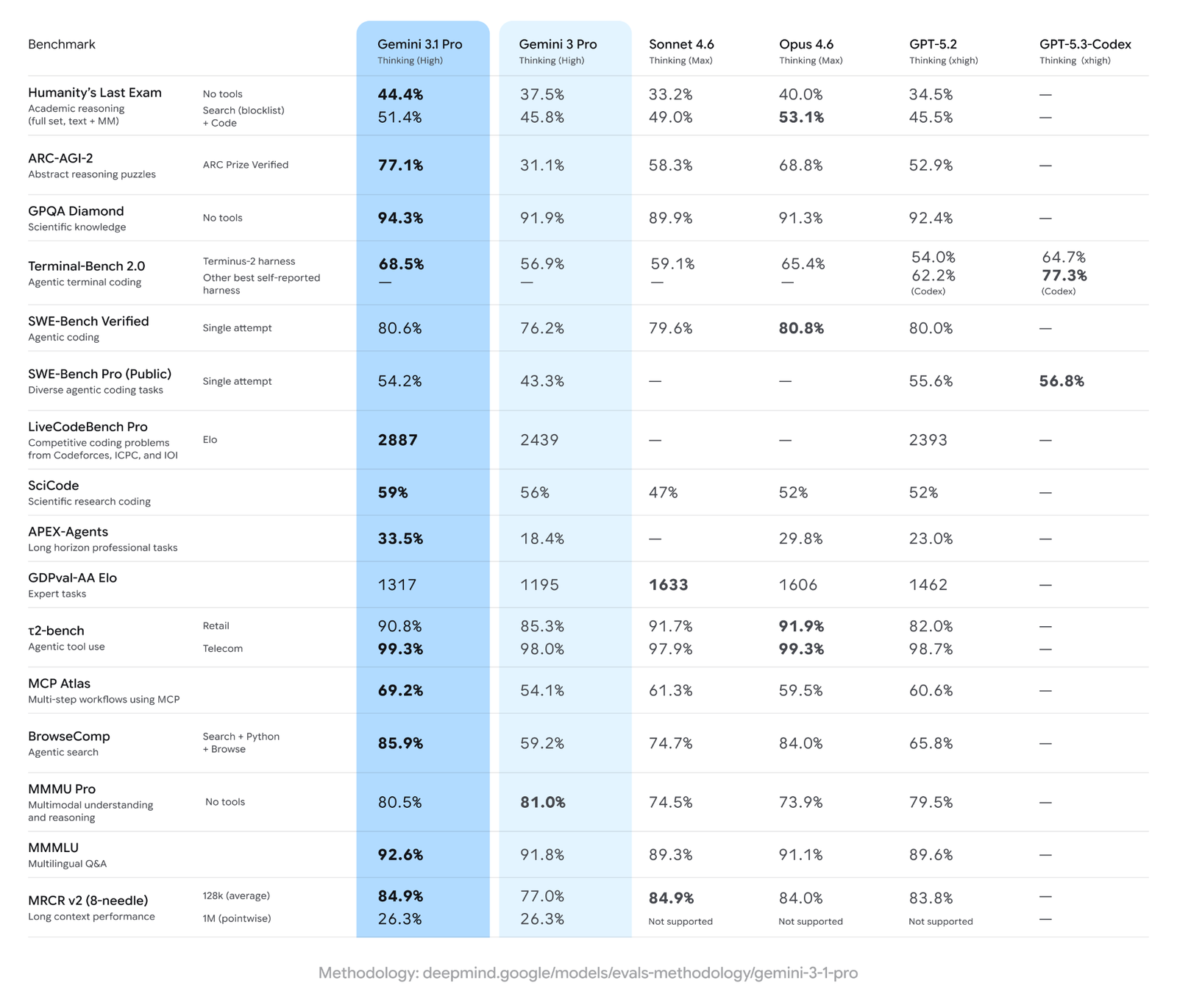
SWE-Bench Verified is the benchmark most developers treat as ground truth. It measures a model’s ability to fix real GitHub bugs across Python repositories. Claude Opus 4.6 scores 80.8% on this benchmark, edging out Gemini 3.1 Pro’s 80.6% by just 0.2 percentage points. That margin is essentially a tie, but Anthropic holds the top line.
LiveCodeBench Pro tells a different story. This benchmark tests competitive programming skill, similar to what you’d find on LeetCode or Codeforces. Gemini 3.1 Pro hits 2887 Elo on this leaderboard, the highest score ever recorded for this benchmark. Opus 4.6 does not match it here.
Terminal-Bench 2.0 measures agentic capability inside a terminal environment. Gemini 3.1 Pro scores 68.5%, which is strong, though GPT-5.3-Codex (using its own harness) reports 77.3% and takes the overall lead in this specific category.
MCP Atlas tests complex multi-step agentic workflows. Gemini 3.1 Pro scored 69.2% against Opus 4.6’s 59.5%, a nearly ten-point gap that favors Google.
ARC-AGI-2 measures novel abstract reasoning, the kind of pattern recognition that can’t be gamed by memorization. Gemini 3.1 Pro scores 77.1%, more than double Gemini 3 Pro’s 31.1%. Opus 4.6 trails at 68.8%, and GPT-5.2 sits further back at 52.9%.
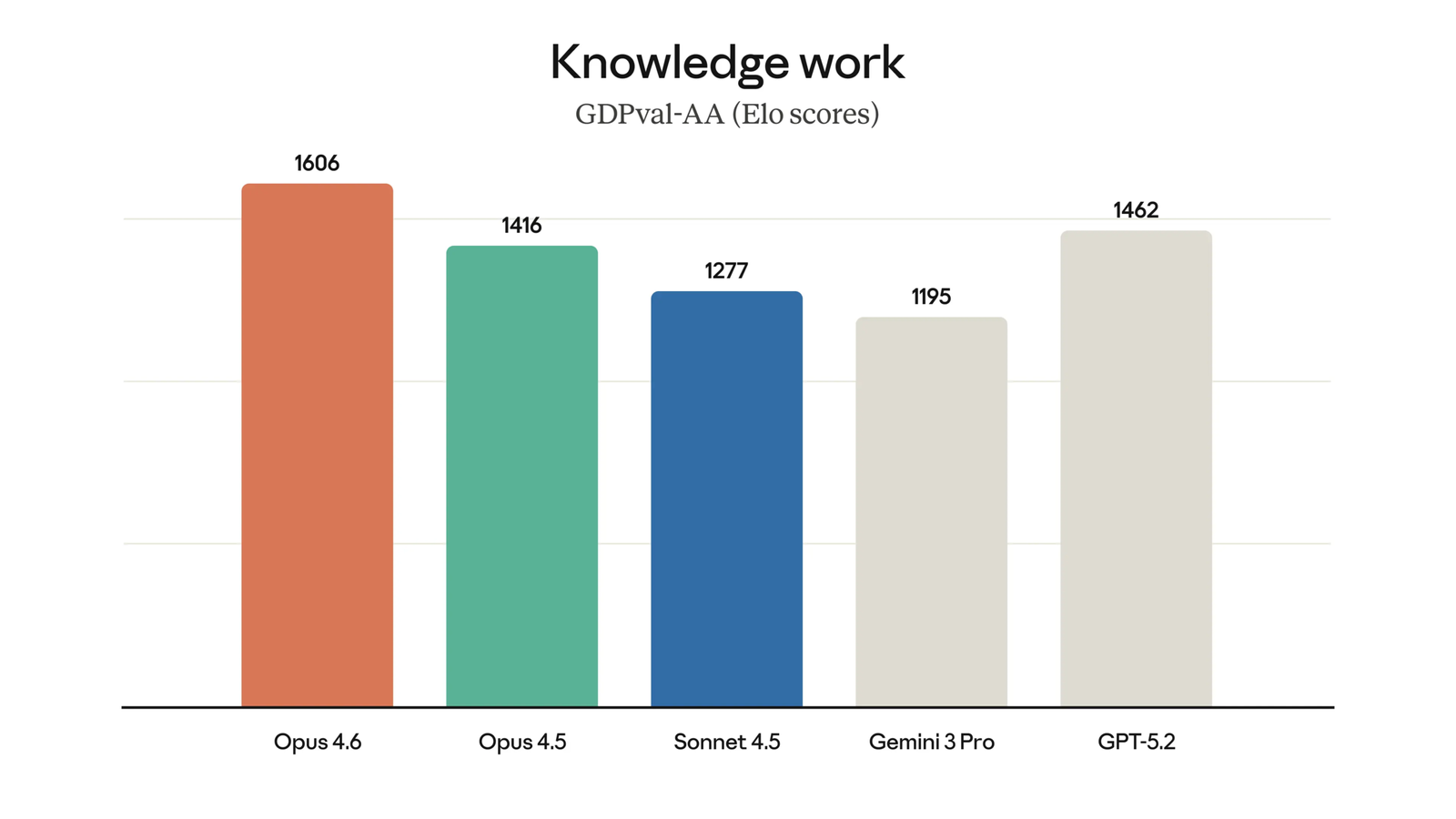
GDPval-AA is the outlier benchmark for Gemini. It evaluates AI performance on expert-level real-world tasks like data analysis and report writing. Claude Opus 4.6 earned a 1606 Elo rating here, while Gemini 3.1 Pro came in at just 1317. Claude Sonnet 4.6 Thinking actually topped this benchmark at 1633 Elo.
Here’s how the core coding benchmarks line up side by side:
| Benchmark | Gemini 3.1 Pro | Claude Opus 4.6 | Winner |
| SWE-Bench Verified | 80.6% | 80.8% | Opus 4.6 (marginal) |
| LiveCodeBench Pro (Elo) | 2887 | Not reported | Gemini 3.1 Pro |
| Terminal-Bench 2.0 | 68.5% | 65.4% | Gemini 3.1 Pro |
| MCP Atlas | 69.2% | 59.5% | Gemini 3.1 Pro |
| ARC-AGI-2 | 77.1% | 68.8% | Gemini 3.1 Pro |
| GDPval-AA (Elo) | 1317 | 1606 | Claude Opus 4.6 |
| HLE with Tools (Search+Code) | 51.4% | 53.1% | Claude Opus 4.6 |
Google claims Gemini 3.1 Pro leads in 13 of 16 benchmarks overall. What that framing misses is which 3 benchmarks Claude still wins, and how relevant those specific benchmarks are to production coding work.
What Each Model Actually Excels At
Understanding the benchmark breakdown is useful, but it becomes more useful when you connect it to specific development scenarios.
Where Gemini 3.1 Pro pulls ahead:
- Competitive programming and algorithmic challenges, where its 2887 Elo on LiveCodeBench Pro is the current best recorded result
- Agentic workflows that involve coordinating multiple tools simultaneously, as shown in MCP Atlas
- Large codebase analysis and refactoring, where the stable 1M token context window gives it an edge
- Scientific and research-adjacent coding tasks: it scores 59% on SciCode, relevant for developers building ML pipelines or research tooling
- High-volume production API calls, where its pricing of $2 per million input tokens is roughly 2.5 to 7.5 times cheaper than Opus 4.6 depending on which pricing tier applies
Where Claude Opus 4.6 holds the edge:
- Real-world software engineering tasks: its 80.8% SWE-Bench Verified score represents the best result on the benchmark most closely tied to production bug-fixing
- Tool-augmented reasoning: Opus 4.6 scores 53.1% on Humanity’s Last Exam with Search and Code tools enabled, compared to Gemini’s 51.4%, suggesting it extracts more value from external tools
- Expert office and knowledge work tasks tied to code: the GDPval-AA gap (1606 vs 1317 Elo) is large and meaningful
- GUI automation: Opus 4.6 scored 72.7% on OSWorld, which tests a model’s ability to operate real desktop GUIs. Gemini 3.1 Pro has not published a score for this benchmark
- Explanatory depth: multiple independent evaluators note that Claude’s generated code tends to come with clearer reasoning and better inline documentation
Gemini 3.1 Pro vs Opus 4.6 Pricing Comparison
Cost shapes real architecture decisions, and this comparison has an unusually large gap.
- Gemini 3.1 Pro: $2 per million input tokens, $12 per million output tokens
- Claude Opus 4.6: $15 per million input tokens, $75 per million output tokens (some sources report $5/$25, so verify current pricing on Anthropic’s official page)
At scale, that difference is not trivial. A team running one billion tokens per month through Opus 4.6 at standard rates could pay dramatically more than the equivalent Gemini workload. Context caching cuts Gemini’s cost further still. For teams where performance is roughly equivalent and budget matters, Gemini 3.1 Pro offers serious price-performance advantages.
The calculus flips when the task specifically demands Opus 4.6’s strengths. Paying more for a model that produces better production-grade code on SWE-Bench class tasks might save money downstream through fewer bugs, fewer review cycles, and cleaner diffs.
Gemini 3.1 Pro vs Opus 4.6 – Context Windows, Integrations, and more
Both models now support 1 million token context windows, though Claude Opus 4.6’s 1M capability is still in beta. Gemini’s implementation is fully stable and has been tested in production for longer. For teams that need to ingest entire repositories, long research papers, or large multi-file codebases in a single prompt, Gemini’s window is the safer choice today.
On output, Claude has a notable advantage. Opus 4.6 can produce up to 128,000 tokens in a single response. Gemini 3.1 Pro caps output at 64,000 tokens. If you need a model to write complete software modules or generate long-form code without interruption, Claude’s output window is more accommodating.
Tool use integration also differs. Claude integrates natively with Claude Code, with VS Code and JetBrains extensions, GitHub pull request review, and MCP-first workflows. Gemini 3.1 Pro integrates with Google AI Studio, Android Studio, GitHub Copilot (in public preview as of February 19), Vertex AI, and Google Antigravity. Your existing stack determines which integrations feel natural.
How to Pick Between Gemini 3.1 Pro vs Opus 4.6?
| Use Gemini 3.1 Pro if: | Use Claude Opus 4.6 if: |
| You’re building competitive programming assistants or algorithmic solvers | Production-grade bug fixing is your primary use case, and the SWE-Bench margin matters to you |
| You need a stable 1M token context window to analyze large repositories | You need a model that extracts maximum value from tool use in augmented reasoning tasks |
| Your code outputs require deep explanatory annotations and a clean structure | Your code outputs require deep explanatory annotations and clean structure |
| You are automating desktop GUI tasks through OS-level workflows | You need output tokens above 64,000 in a single generation |
| Your budget is tight, and you’re running high-volume inference | You work with multimodal inputs, including video or audio, alongside code |
| Your stack is Google Cloud or Vertex AI native | Expert knowledge work tied to code, like generating technical specifications or data analysis, is central to your workflow |
Notes on Code Quality Beyond Benchmarks
Benchmark scores measure task completion, but code quality is a separate dimension. Research from Sonar, published in December 2025, tracked models on pass rate, cognitive complexity, and code verbosity. Gemini 3 Pro (the predecessor to 3.1 Pro) had the highest rate of control flow mistakes among the models tested, at 200 per million lines of code. That’s nearly four times the rate observed for Opus-class models. Gemini 3.1 Pro is newer and likely improves on this, but the pattern across Gemini generations is worth watching if your team reviews generated code carefully.
Code verbosity also varies meaningfully. Gemini 3 Pro produced concise, low-complexity code relative to its pass rate. Claude’s Opus-class models tend toward more verbose output. Depending on whether you value concision or thoroughness, that behavioral difference can matter in practice.
Wrapping Up
Gemini 3.1 Pro and Claude Opus 4.6 are excellent choices in their own right. Picking between them depends on which part of the development workflow you want to optimize. Gemini 3.1 Pro is the better choice for competitive programming, large-context codebase work, agentic tool coordination, and situations where cost is a constraint. Claude Opus 4.6 excels in bug-fixing, expert knowledge tasks, and cases that require long generated outputs. For most teams, neither model wins in every area. A routing strategy that sends SWE-class tasks to Opus 4.6 and high-volume or competitive coding tasks to Gemini 3.1 Pro captures the strengths of both. So assigning each a different purpose should be helpful.