

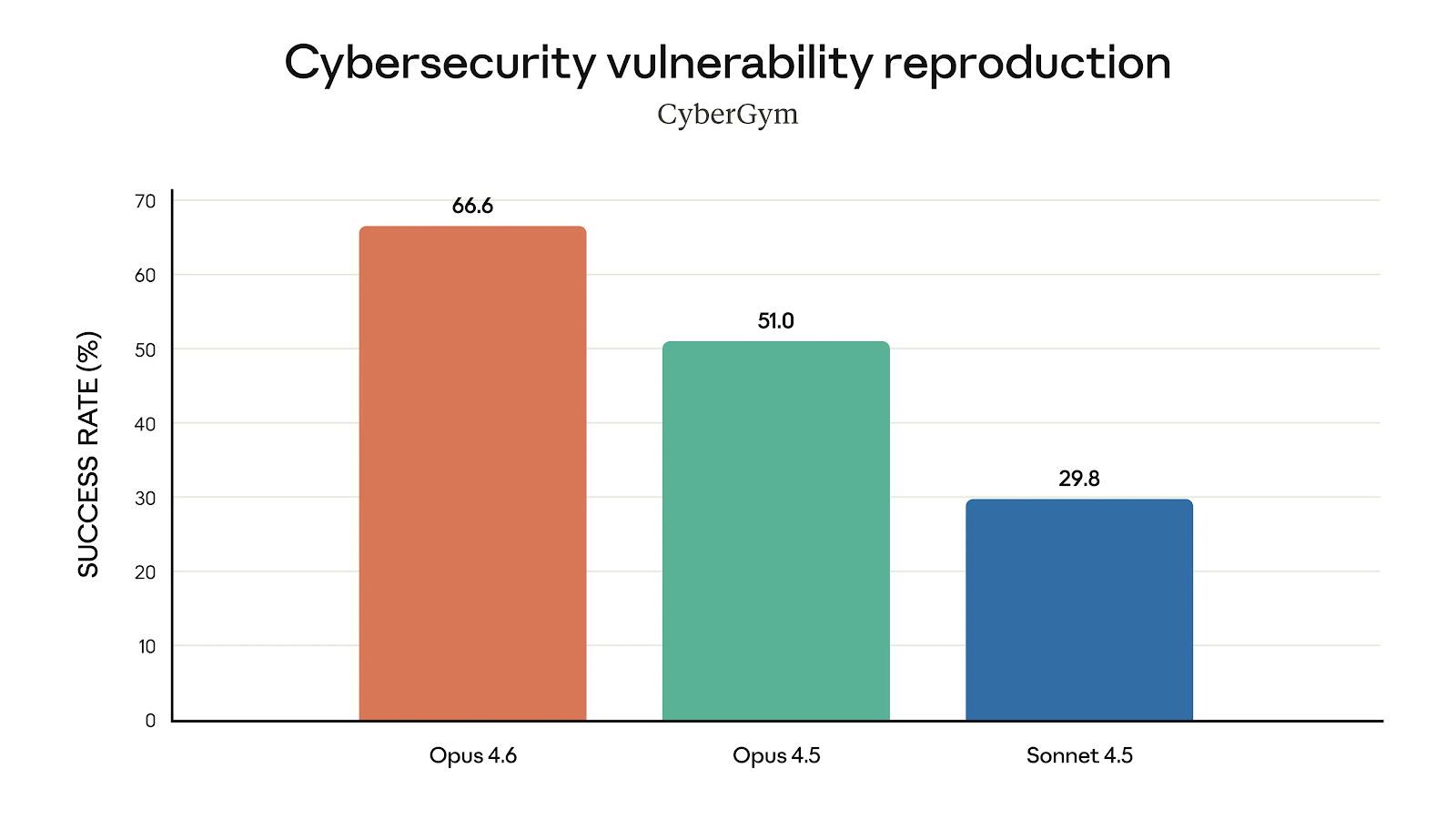
If you’ve followed LLM releases in the past 1-2 years, you know small version jumps can hide massive capability shifts. The most recent example is the release of Claude Opus 4.6. What makes this release stand out is not just incremental gains but measurable leaps in agent workflows, context reliability, and enterprise benchmarks. For example, early testing shows Opus 4.6 winning 38 out of 40 cybersecurity investigations against Opus 4.5 variants, which hints at more than a routine upgrade.
AI model updates used to focus mostly on raw intelligence scores, and that trend still matters because benchmark wins translate into real-world productivity. At the same time, enterprise adoption now depends on consistency, long session stability, and autonomous task execution, which shifts the conversation from “Is it smarter?” to “Can it actually run work end-to-end?”
That shift explains why Opus 4.5 felt revolutionary when it launched. It pushed coding automation past the human-level threshold on SWE-bench Verified, scoring 80.9%, which was the first time any model or human benchmark crossed that line.
Because of that milestone, Opus 4.5 became the default “serious work” model for many teams. Then Opus 4.6 arrived, and instead of just improving accuracy, it expanded what long-running AI work can even look like.
What Made Claude Opus 4.5 So Strong
Opus 4.5 set expectations by proving LLMs could move beyond assistants into autonomous collaborators. That transition matters because enterprises do not just want answers; they want execution.
Where Opus 4.5 Excelled
Coding dominance
- 80.9% SWE-bench Verified score, beating all competitors and humans
- Industry-leading performance on real GitHub issue resolution
- Terminal-Bench Hard leader at 44% accuracy
- Strong agent coding performance across multi-step workflows
Reasoning and general intelligence
- ~90% MMLU and MMLU-Pro level performance
- 87% GPQA Diamond level reasoning
- Strong ARC-AGI-2 reasoning performance
Agent workflows
- OSWorld score around 66.3%, showing strong computer-use ability
- High performance on multi-step planning tasks
Cost efficiency
- Pricing cut to $5 input and $25 output per million tokens
- Up to 90% savings with prompt caching in some workflows
These metrics mattered because they combined raw intelligence with production viability. That combination helped Opus 4.5 rank near the top of global model intelligence indexes while keeping costs manageable for enterprise deployment.
But once teams began running multi-hour agent loops, another bottleneck appeared, which is where Opus 4.6 enters the story.
What Claude Opus 4.6 Actually Changed
Opus 4.6 is less about single-task accuracy and more about sustained intelligence over time. That distinction matters because modern AI workloads are rarely single-prompt problems.
Major Capability Upgrades
Massive context expansion
- Standard 200K tokens remain.
- New 1 million token context window in beta
Agentic reasoning upgrades
- Adaptive thinking replaces static extended reasoning.
- Effort-level controls allow dynamic compute allocation.
Output capacity increase
- Output limit doubled from 64K to 128K tokens.
Parallel agent workflows
- “Agent Teams” allow multi-agent task distribution.
Long session optimization
- Context compaction automatically summarizes old context.
These upgrades matter because long context reliability directly affects codebase navigation, legal review, and research synthesis tasks. The 1M token window alone allows entire repositories or document archives to stay in active working memory.
And critically, Anthropic kept pricing the same, which changes the cost-performance equation dramatically.
Claude Opus 4.5 vs Claude Opus 4.6 – Benchmark Improvements That Matter
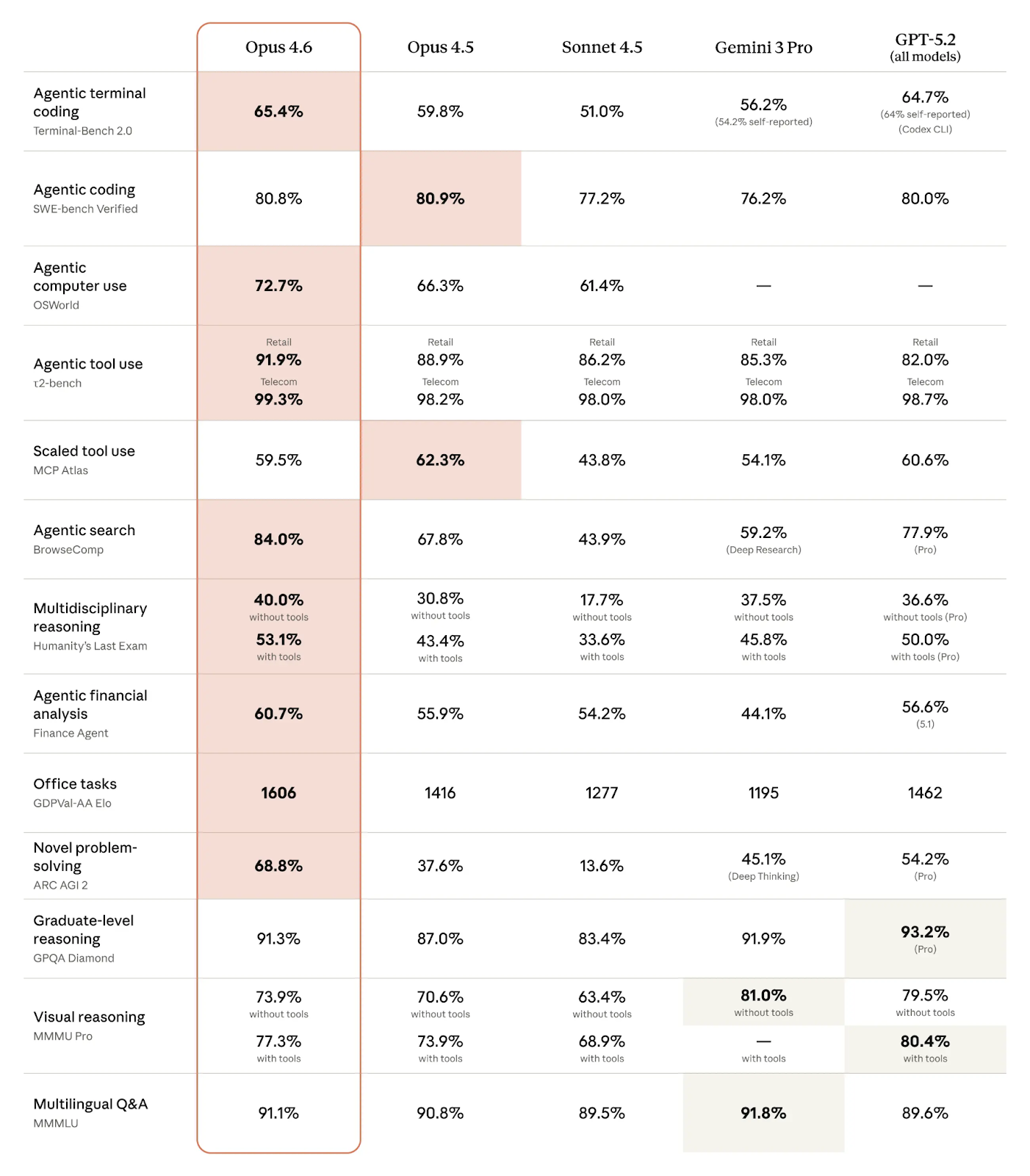
While marketing features get attention, benchmark movement usually reveals the real story. Here are the most meaningful signals from early data.
Performance Gains Over Opus 4.5
| Benchmark | Opus 4.6 Performance | Opus 4.5 Comparison |
| Terminal-Bench 2.0 | 65.4% | Lower baseline range |
| GDPval-AA | ~190 Elo improvement | Baseline |
| OSWorld | ~72.7% | ~66% |
| Cybersecurity testing | Won 38/40 blind evaluations | Opus 4.5 (lost majority) |
| BigLaw Bench | 90.2% (highest for any Claude) | N/A |
These numbers suggest the biggest gains are in applied reasoning and tool usage, not just raw test intelligence.
That distinction is important because enterprise AI ROI depends more on reliability than peak benchmark scores.
Claude Opus 4.5 vs Claude Opus 4.6 – Side-by-Side Comparison
| Context Window | 200K tokens | 200K standard, 1M beta |
| Output Limit | 64K tokens | 128K tokens |
| Thinking Mode | Extended thinking | Adaptive thinking |
| Terminal Bench 2.0 | ~59% range | 65.4% |
| OSWorld | ~66% | ~72.7% |
| Pricing | $5 / $25 per MTok | Same pricing |
| Enterprise Workflow Support | Strong | Significantly stronger |
This table shows why Opus 4.6 is being positioned as a workflow model rather than just a smarter chatbot.
Claude Opus 4.5 vs Claude Opus 4.6 – Real-World Workflow Differences
Benchmarks matter, but real production usage reveals where upgrades actually land.
Where Opus 4.6 Feels Noticeably Better
- Long-running agent tasks
- Large codebase refactoring
- Multi-document research synthesis
- Financial modeling and spreadsheet reasoning
- Legal document analysis
- Cross-tool workflow automation
This improvement exists because Opus 4.6 was built around agent orchestration rather than single prompt performance. Enterprise users report fewer required revisions when generating business documents and analytics outputs.
And that improvement directly reduces human review overhead, which is where most AI deployment cost hides.
Where Opus 4.5 Still Holds Ground
Despite the upgrade, Opus 4.5 still matters for certain use cases.
Situations Where 4.5 May Still Be Enough:
- Pure coding tasks with shorter context
- High-throughput automation where context depth is irrelevant
- Teams are already optimized around Opus 4.5 prompt patterns.
- Scenarios where adaptive reasoning variability is not needed
Opus 4.5 remains one of the best pure coding models ever released, especially on SWE-bench style real engineering tasks.
That means the upgrade is not mandatory for every team.
Strategic Direction: What Opus 4.6 Signals About AI
The jump from 4.5 to 4.6 signals a broader shift in how frontier models are evolving.
The New Model Design Priorities:
- Persistent memory across sessions
- Autonomous task execution
- Multi-agent coordination
- Long-horizon reasoning stability
- Enterprise integration first, consumer later
Anthropic is clearly targeting knowledge work automation rather than conversational AI dominance. That strategy is reinforced by strong performance in finance, legal, and enterprise analysis workloads.
And that focus may shape how future frontier models compete.
Claude Opus 4.5 vs Claude Opus 4.6 – The Hidden Tradeoffs
Every capability upgrade comes with tradeoffs, even if marketing does not emphasize them.
Potential Downsides to Consider:
- Higher compute cost for deep reasoning sessions
- Possible variability from adaptive thinking modes
- Larger context increases prompt management complexity.
- Some anecdotal feedback suggests that writing style can feel less natural when optimized for reasoning.
These tradeoffs matter because teams often over-index on benchmark improvements without modeling real workflow impact.
Wrapping Up
The move from Claude Opus 4.5 to 4.6 isn’t a total reinvention. More so, a refinement of the “workload engine.” While 4.5 remains a powerhouse for pure coding and high-level reasoning, 4.6 focuses on the connective tissue, the stuff that happens between the prompts.
It offers a more stable experience in sustained reasoning and agent orchestration, making it a steadier hand for the long-context reliability that enterprise workflows demand. It’s less about a massive power jump and more about operational maturity. And since they cost alike, a decision between them should be easy.



